While browsing through the FAQ, we discovered that it uses gensim word2vec (they called it AI.. lol). Gensim is a NLP (Natural Language Processing) library for python. Word2vec is a process which vectorizes words by comparing them to words around them in a corpus (the input data set, usually a book or collection of articles).
How does word2vec work?
The vector generated for each word, which is the output of the process, is referred to as an embedding. Gensim supports two techniques of vectorization, CBOW (Continuous Bag of Words) and Skip-Gram
CBOW
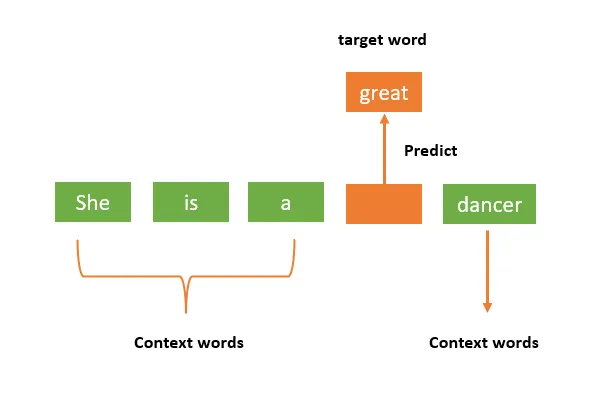
CBOW uses the several words before and after the word of interest as a training input.
Each context word is represented as a one-hot vector, which is an RN vector where N is equal to the total number of unique words in the corpus. The one-hot vectors of the words in the context window are summed together to produce training input. For example.
If the entire corpus (generally massive) is: “the cat jumped over the mouse because his mother was sad”
Then the one hot vectors could be:
“jumped”: [1000000000]
“the”: [0100000000]
“cat”: [0010000000]
“over”: [0001000000]
“mouse”: [0000100000]
“mother”: [0000010000]
“because”: [0000001000]
“his”: [0000000100]
“was”: [0000000010]
“sad”: [0000000001]
Note that the order of these is arbitrary, and N is equal to the number of unique words in the corpus.
To train a word, the one-hot vectors of the words inside the context window are summed into a single training vector.
If the window size is 3 before and 1 after (like in the picture), the training context vector for the second occurrence of “the” in our example corpus would be:
[1011100000]
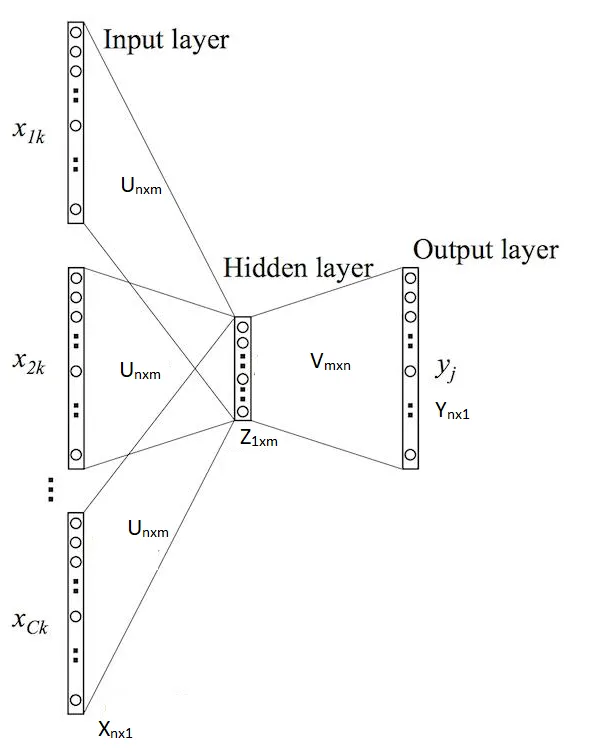
A simple-ish neural network is trained to predict the word in question using this context vector for each word in the corpus, so for our example, there would be 11 context vectors and 11 trainings.
The structure of network used allows for a hidden layer of arbitrary size.
The output we want isn’t a prediction model. We want the embedding of each word. The weights between the input and hidden layer are directly used to produce the embedding of each word. Because we can choose the size of the hidden layer, we can choose the degree of our embeddings.
Skip-Gram
Explanation To-Do
What worked
The data set used by both proximity and semantle has R300 embeddings, is generated via CBOW and uses google news as corpus.
Our current code:
from gensim import models w = models.KeyedVectors.load_word2vec_format( 'wordvectors.bin', binary=True) print(w) word=input("word here: ") similarity=float(input("similarity score: "))/100word2=input("word2 here: ") similarity2=float(input("similarity2 score: "))/100words = w.most_similar(word, topn=20000) #words2 = w.similarity(word, word2) for _w in words: if (similarity-0.0001)<_w[1] and _w[1]<(similarity+0.0001): if (w.similarity(_w[0], word2))>(similarity2-0.0001) and (w.similarity(_w[0], word2))<(similarity2+0.0001): if "_" not in _w[0]: print(_w)
Import gensim and the google news model
The user guesses two words, and inputs the words they tried and their similarity to the target word as returned by semantle.
The similarities are converted to the format used by gensim (from a percent to a scalar)
We ask gensim for the 20000 most similar words to the first quess
We go find the subset of those 20000 words which are in the proper range for the similarity score semantle gave the user
From those words, we find the ones that are in the correct range of similarity to the second user guess
Filter any words with underscores
Return the list of matching words (usually length < 3 and some are weird enough to rule out manually)
Some notes about how gensim determines similarity
The code we wrote to search for words of appropriate similarity uses the keyedVector.similarity() method. The definition of that method is shown below
However this is not the same as the normal way to calculate euclidean distance,
d=(774−141)2+(775−71)2+(776−143)2
Gensim’s “distance” function dosen’t really return distance as we think about it.. even normalized distance. I couldn’t find any hint in the documentation or internet as to why 1-cosine similarity is referred to as distance.